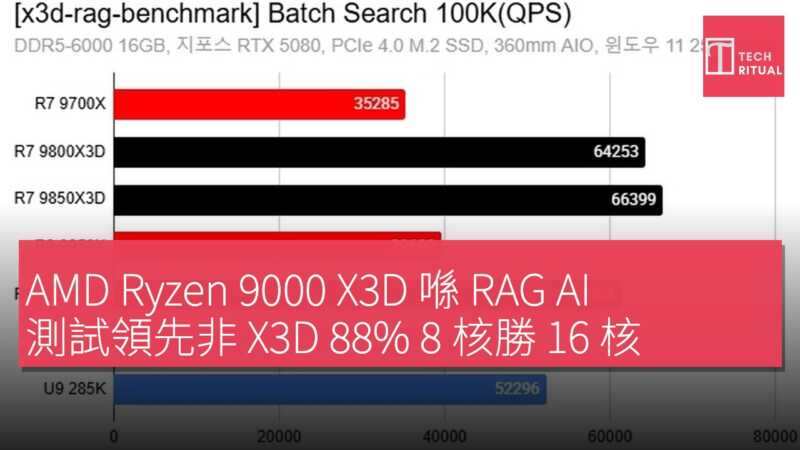
根據 GiggleHD 實測,AMD X3D 處理器在 RAG(檢索增強生成)AI 基準測試中展現遠超預期的性能,最高領先非 X3D 晶片達 88%。RAG AI 透過外部向量資料庫檢索資訊來增強大模型的回應品質,與純 LLM 推理不同,向量搜尋的大量計算負載落在 CPU 而非 GPU 上。隨著 Agentic AI 工作負載的推進,搜尋驅動的任務越來越多,CPU 的延遲瓶頸問題日益凸顯。
HNSW(階層可導航小世界)搜尋演算法即為典型例子,在 GPU 執行 LLM 推理的同時,CPU 負責圖檢索,更大的快取意味著更短的檢索時間。
測試規格與性能數據
GiggleHD 使用開源的 X3D RAG 基準測試,針對個人 PC 和小團體單節點場景(約 100K-200K 向量),對 AMD 龍驤 9000X3D 系列及多款非 X3D 晶片進行實測。結果顯示,在 100K 向量批次搜尋中,X3D CPU 最高比非 X3D 晶片快 88%;在 200K 向量測試中,同為 8 核的龍驤 7 9850X3D 比龍驤 7 9700X 快 50% 以上,且 8 核 X3D 晶片的速率超過 16 核的龍驤 9 9950X。
| 測試項目 | 100K 向量 | 200K 向量 | |———-|———–|———–| | X3D 搜尋速度領先非 X3D | 最高 88% | 龍驤 7 9850X3D 領先龍驤 7 9700X 50%+;8 核 X3D 超 16 核龍驤 9 9950X | | 索引建構時間縮短 | 50% | 39% | | RAG 生成量 | X3D 領先 | X3D 領先 |
索引建構方面,100K 向量測試時間縮短 50%,200K 縮短 39%,並發 RAG 生成量同樣由 X3D 晶片領先。差異較小的項目為 TTFT(首 Token 時間)生成量,因該任務主要依賴 GPU 而非 CPU。
