DeepSeek 如何利用更少的數據和顯卡,打造出能與國際巨頭抗衡的模型,值得關注。
新技術與創新
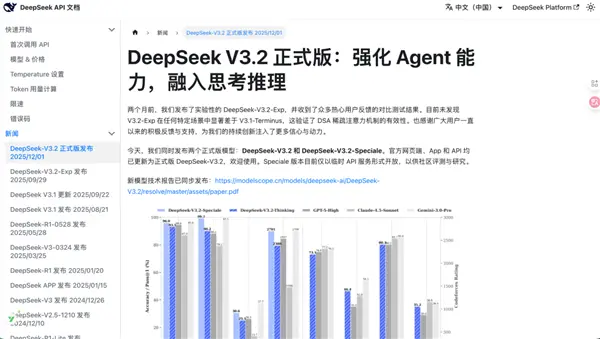
為了達成這一目標,DeepSeek 引入了一系列新技術,包括稀疏注意力(DSA)。這一技術在之前的 V3.2-EXP 版本中進行過測試,這次則成為主力模型的一部分。大模型在對話過程中,隨著交談的增長,往往會出現胡言亂語的情況,甚至可能完全中斷對話。這是因為傳統的注意力機制要求每個 token 與前面的每個 token 之間進行計算,導致計算量隨著句子增長而大幅增加。 DeepSeek 通過在模型中增加固定頁數的目錄,來幫助模型更有效地進行長文閱讀。每次只需要計算當前 token 與這些目錄的關係,從而提高處理長文本的能力。實驗顯示,使用了稀疏注意力的 V3.2 模型在推理成本上幾乎沒有增長,相比之下,傳統的 V3.1 模型則隨著句子增長而推理成本不斷上升。 此外,DeepSeek 開始重視模型的後訓練工作。開源模型在這一階段的投入往往較少,導致模型的表現未能達到最佳。DeepSeek 決定設計一套新的強化學習協議,為模型的後訓練階段投入超過 10% 的算力,從而彌補之前的不足。特別版的 DeepSeek V3.2 Speciale 取消了長度限制,鼓勵模型自由思考,這使得其在與 Gemini 3 的競爭中佔據了一席之地。
DeepSeek 也重視模型在智能體方面的能力,通過構建虛擬環境並合成大量數據來輔助訓練,DeepSeek-V3.2 在後訓練過程中使用了24667個真實代碼環境任務、50275個真實搜索任務等多種真實任務來提升模型表現。 同時,DeepSeek 還優化了模型使用工具的流程,確保在調用外部工具時模型的思考過程不會中斷,這樣可以大幅提高用戶的體驗。這些改進讓 DeepSeek 的新模型具備了與世界頂尖開源模型一較高下的能力。 儘管 DeepSeek 在多方面有所進步,但表現依然不算完美。根據研究,DeepSeek V3.
2 Speciale 在回答問題時,所需 token 數量較高,這一點在與 Gemini 3 Pro 的比較中得以顯示。測試結果顯示,Gemini 只需 4,972 個 token,而 DeepSeek 則需 8,077 個 token,顯示出一定的差距。然而,從價格方面來看,DeepSeek 的費用相對較低,使用 8,000 多個 token 僅需 US$0.00 (約 HK$0),而 Gemini 在使用 5,000 個 token 時則需 US$0.06 (約 HK$0),顯示出 DeepSeek 在性價比上的優勢。 在開源模型與閉源模型的競爭中,DeepSeek 正在努力縮小這一差距,通過節省算力和數據的策略,展現出其獨特的發展方向。
這不禁令人想起 Ilya Sutskever 的觀點,即單靠堆砌參數並無未來,算法的研究同樣重要。DeepSeek 的進步不僅依賴於參數規模的提升,更在於如何用有限的數據創造更多的智能。
想睇更深入嘅 AI 模型與工程科技報道?
前往 The Base Principle 繁體中文 AI 新聞 →