



香港,2023年8月3日 — 阿里巴巴集團的數字技術與智能骨幹業務阿里雲宣佈,將兩款70億參數開源大語言模型Qwen-7B 及Qwen-7B-Chat,於其AI模型社區ModelScope及AI協作平台Hugging Face上架,以此為開源生態做出貢獻。
今年4月,阿里雲推出自研大語言模型通義千問。這一前沿的模型可生成類似於人類表達的中英文雙語內容,還包括70 億及以上參數量級不同的模型規模。此次阿里雲發布的開源版本包括預訓練的 70 億參數基座模型 Qwen-7B 和基於這一模型微調的對話模型 Qwen-7B-Chat。
為進一步助力AI技術普惠,全球學術、研究及商業機構均可免費獲取上述模型的代碼、模型權重和文檔。對於商業應用需求,月活躍用戶少於1 億的公司可免費使用模型,用户數超過該量級的企業可向阿里雲申請許可證。
阿里雲智能集團首席技術官周靖人表示:「透過開源自研的大語言模型,我們旨在促進技術普及,並令生成式AI惠及更多的開發者及中小企。阿里雲一直不遺餘力地推進不同的開源舉措,我們期待這一開放的模式能啟發更多集體智慧,並進一步促進開源社群的蓬勃發展。」
Qwen-7B 在超過 2 萬億token數據集上預訓練,涵蓋通用和專業領域的中英文及其他多語種資料、代碼和數學內容,上下文窗口長度達到 8千。在訓練過程中,Qwen-7B-Chat 模型已經與人類認知對齊。Qwen-7B和Qwen-7B-Chat模型均可部署在雲端及本地基礎設施上,便於用戶對模型微調,以高效、低成本的方式搭建適合自身使用的優質生成式AI模型。
Qwen-7B 預訓練模型於英文能力基準測評MMLU(大規模多任務語言理解)中表現突出,得分高達 56.7,超越一眾具有類似規模或更大規模的主流預訓練開源模型。這一測評旨在考驗文本模型在 57 個不同任務中處理多任務的準確性,涵蓋初等數學、計算機科學和法律等多個領域。在中文常識能力測試集C-Eval 上,Qwen-7B 同樣在同等參數模型中脫穎而出,在Leaderboard獲得最高分。該測評集涵蓋了人文、社會科學、STEM 等四大專業領域的 52 個學科。此外,Qwen-7B 在包括 GSM8K 和 HumanEval 等數學和代碼生成基準測評中亦表現出眾。
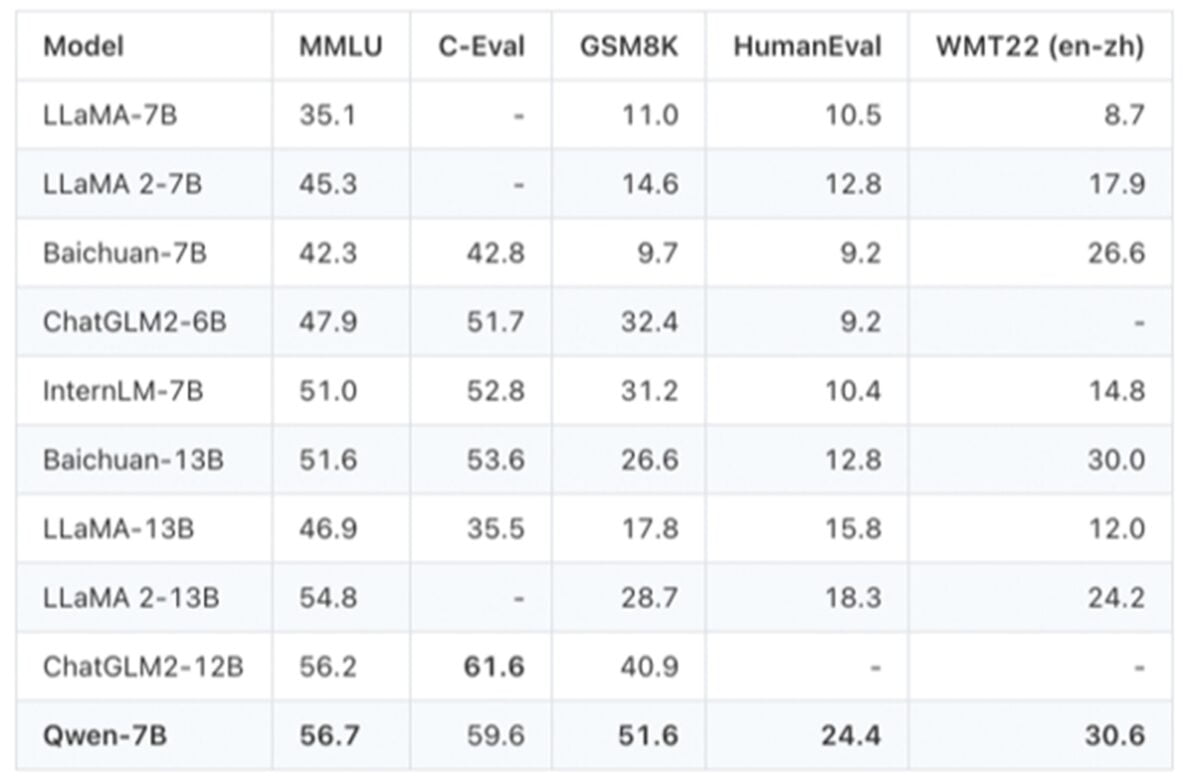
阿里雲的Qwen-7B模型於數個基準測評中均表現出眾
今年7月,阿里雲發佈了最新AI繪畫創作大模型「通義萬相」,旨在支持開發者和中小企業開展創新的圖像藝術表達。阿里雲亦於7月宣佈推出通用框架ModelScopeGPT,旨在協助用戶透過使用ModelScope平台上的多元AI模型完成各類極複雜和專業的AI任務,適用領域包括語言、視覺和語音等。ModelScope開源平台由阿里雲於去年推出,目前匯集由20家全球領先AI機構提供的1000多個AI開源模型。
如欲了解更多詳情,請瀏覽ModelScope 、HuggingFace及GitHub的Qwen-7B和 Qwen-7B-Chat模型網頁。
###
