11月27日晚,DeepSeek 在 Hugging Face 上悄然發佈了一個新模型:DeepSeek-Math-V2。這個模型專注於數學領域,並且是目前業界首個達到 IMO(國際奧林匹克數學競賽)金牌水平且開源的模型。
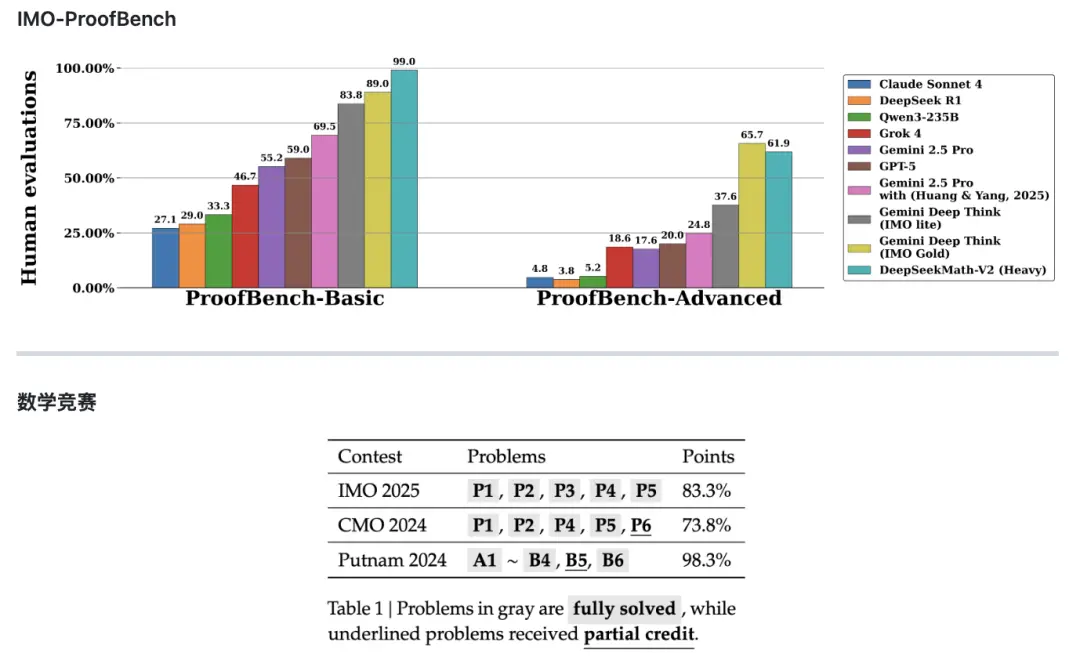
在同時發布的技術論文中,DeepSeek 表示,Math-V2 的部分性能優於 Google 旗下的 Gemini DeepThink,並展示了該模型在 IMO-ProofBench 基準以及近期數學競賽中的表現。具體來看,在 Basic 基準上,DeepSeek-Math
-V2 以近 99% 的高分遠超其他模型,而排名第二的 Google 旗下 Gemini DeepThink (IMO Gold) 分數為 89%。但在更具挑戰性的 Advanced 子集上,Math-V2 的分數為 61.9%,略遜於 Gemini DeepThink (IMO Gold) 的 65.7%。
在名為《DeepSeek Math-V2:邁向可自驗證的數學推理》的論文中,DeepSeek 指出,大語言模型在數學推理方面已取得重大進展,這是人工智能的重要試驗台,若進一步推進,可能會對科學研究產生影響。
然而,目前的 AI 在數學推理方面存在研究局限:以正確的最終答案作為獎勵,但正確的答案並不一定保證推理過程的正確性。許多數學任務,如定理證明,需要嚴謹的分步推導,而非僅僅是數字答案,這使得最終答案的獎勵不適用。
為了突破深度推理的極限,DeepSeek 認為有必要驗證數學推理的全面性和嚴謹性。團隊提出,自我驗證對於擴展測試時間計算特別重要,尤其是針對那些沒有已知解決方案的開放問題。此次推出的 Math-V2 從結果導向轉向過程導向,展示了強大的定理證明能力。該模型不依賴於大量的數學題答案數據,而是通過教會 AI 像數學家一樣嚴謹地審查證明過程,從而在沒有人工介入的情況下,持續提升解決高難度數學證明題的能力。
論文提到,Math-V2 在 IMO 2025 和 CMO 2024 上取得了金牌級成績,在 Putnam 2024 上通過擴展測試計算實現了接近滿分的成績(118/120)。DeepSeek 認為,雖然仍有許多工作要做,但這些結果表明,可自我驗證的數學推理是一個可行的研究方向,可能有助於開發更強大的數學 AI 系統。
對於 DeepSeek 的此次動作,海外反應為「鯨魚終於回來了」。有網友感慨,DeepSeek 以 10 個百分點的優勢擊敗 Google 的 IMO Gold 獲獎模型 DeepThink,這不在預測範圍內。
「想像一下,當他們公布編程模型時會發生什麼,我打賭他們絕對有編程模型。」目前,行業頭部廠商的模型已經又迭代了一輪,11 月,先是 OpenAI 發布了 GPT-5.1,幾天後 xAI 發布 Grok 4.1,就在上周 Google 發布了 Gemini 3 系列引爆 AI 圈,「也該輪到 DeepSeek 出牌了」。不過,更受外界關注的仍然是,DeepSeek 的旗艦模型到底什麼時候更新,行業期待「鯨魚」的下個動作。
