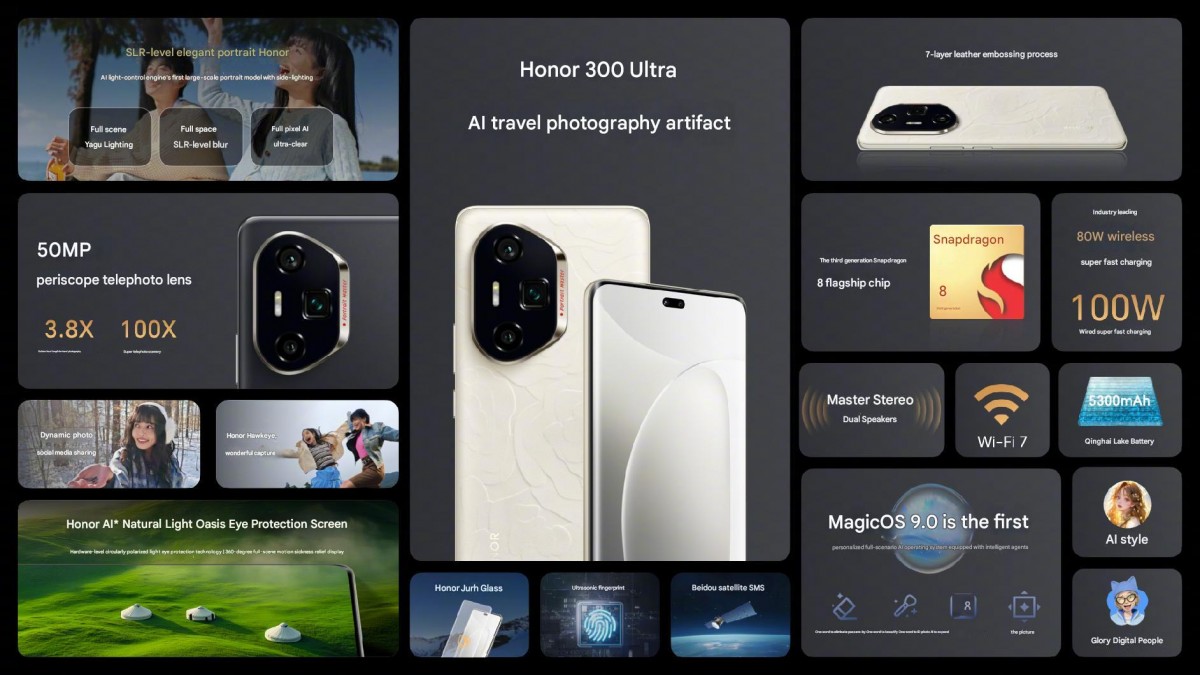
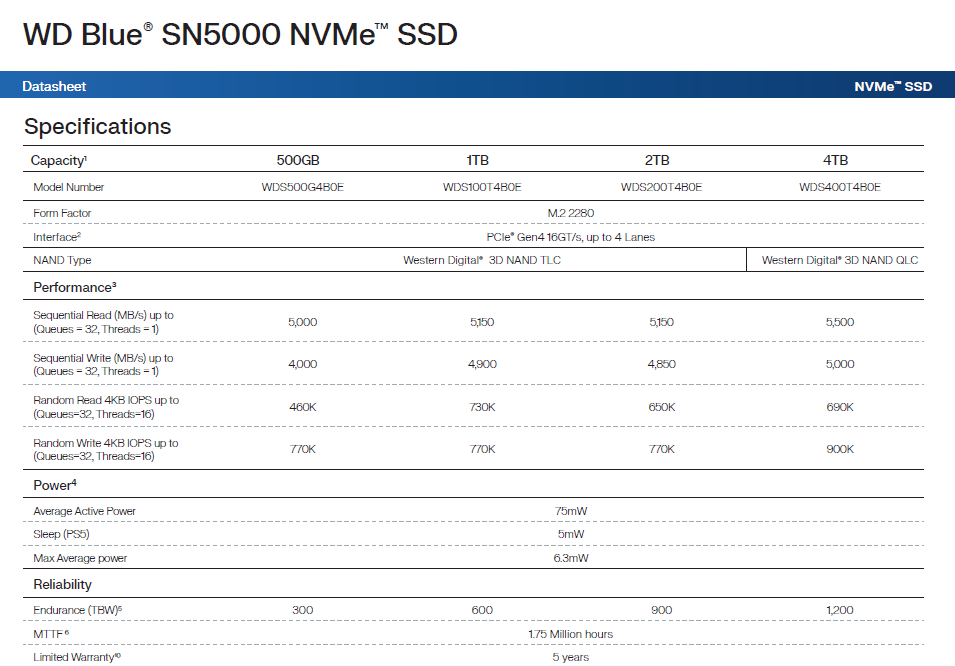
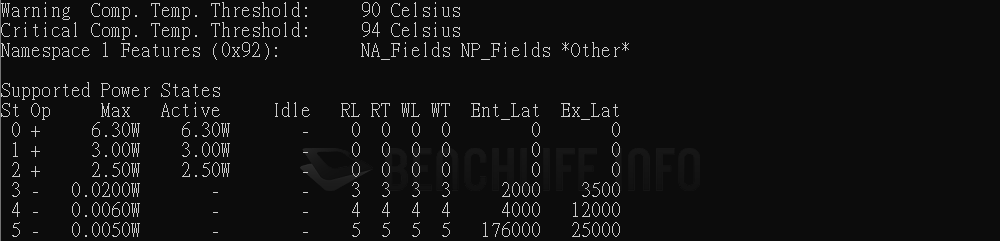
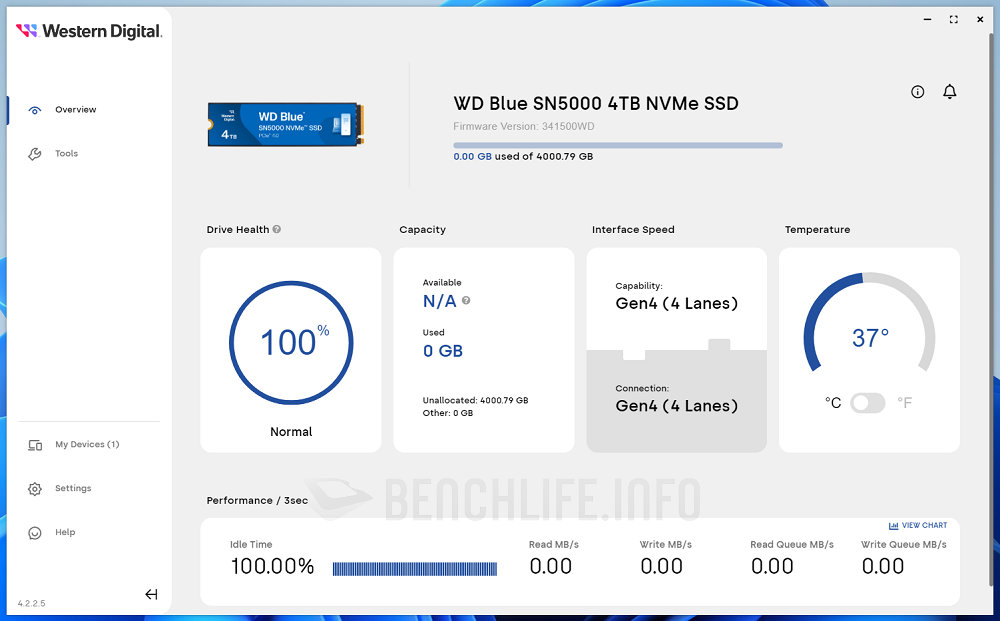
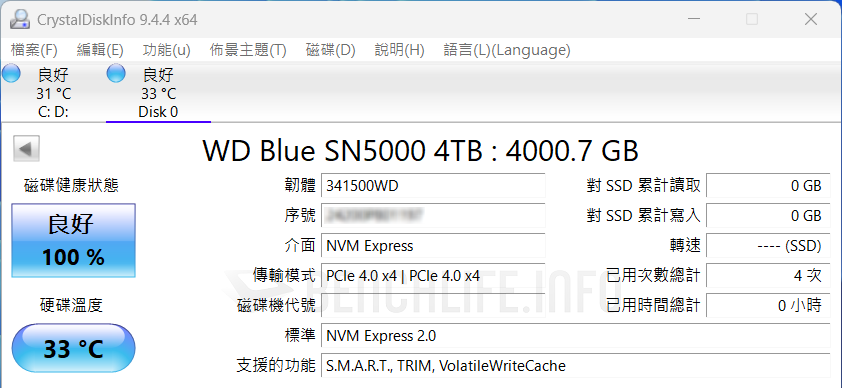
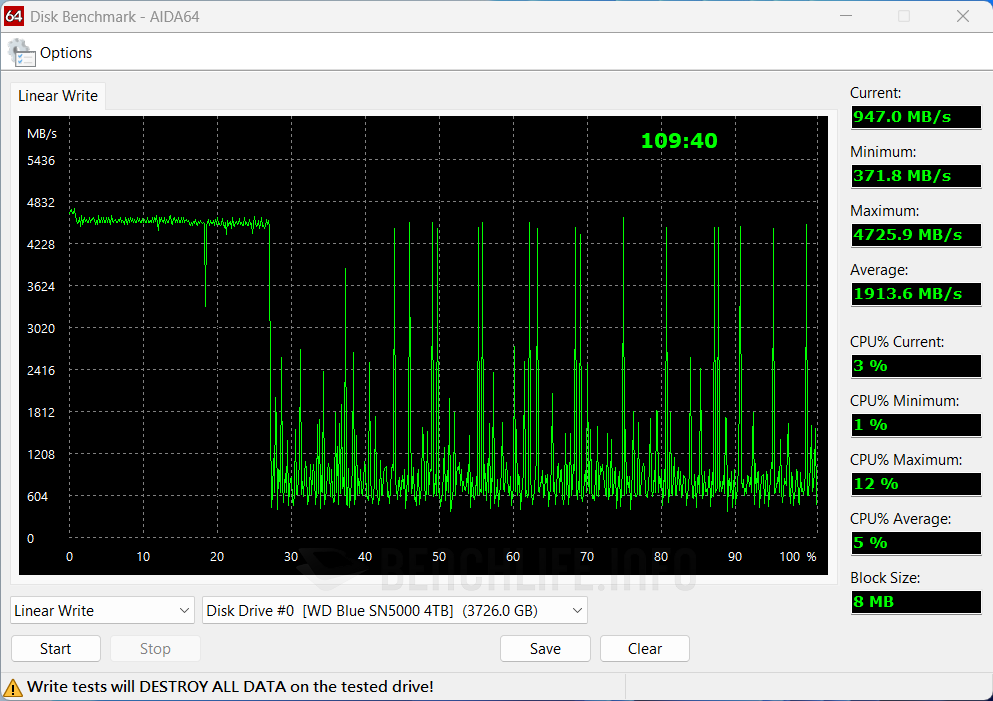
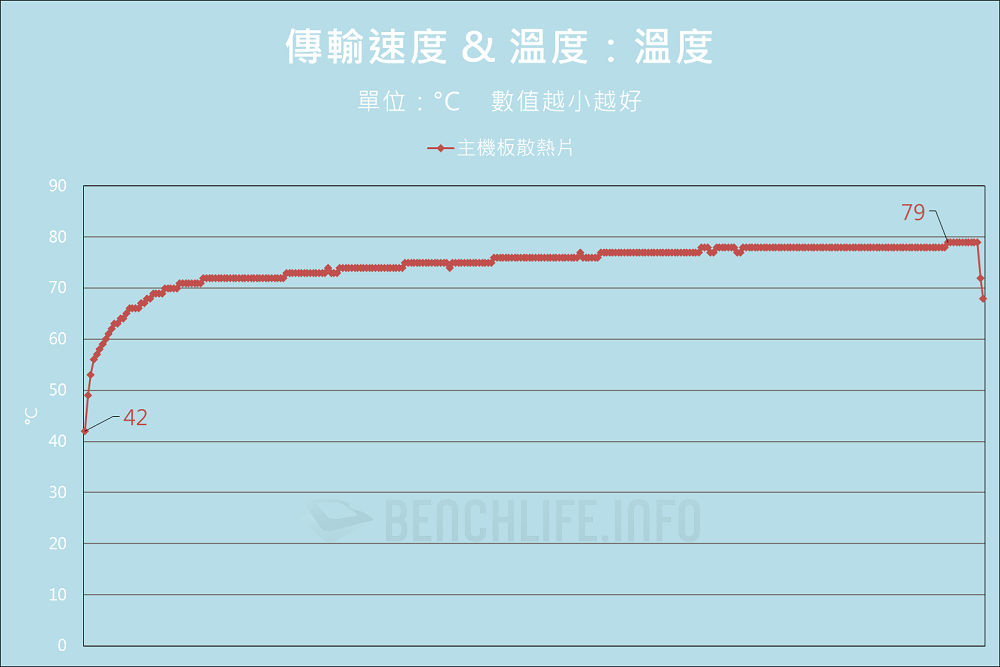
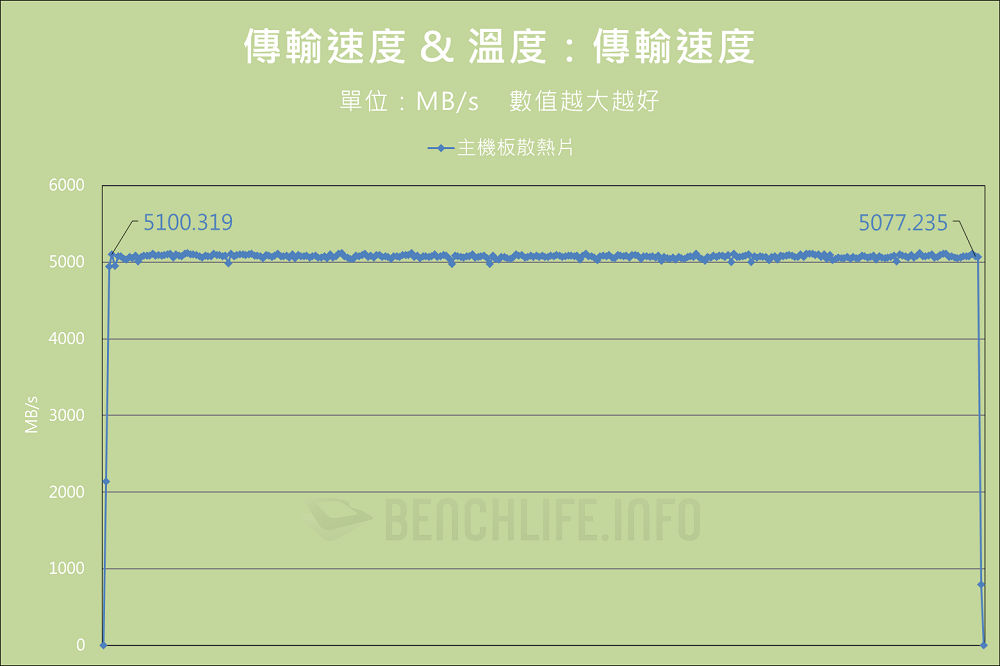
我們認為 Western Digital 對於 DRAM-less 產品的設計調校策略,以及 WD Blue SN5000 4TB 使用 QLC 3D NAND,是導致前述現象的主因。總之最佳表現仍以 CrystalDiskMark 作為代表,Q32T16 條件下達到讀取 727.364.5IOPS、寫入 910.008.06IOPS,是有高於官方標示值。
一名 Tesla 車主分享了其 Model 3 Long Range 後驅版 (RWD) 的驚人數據。根據這位車主的說法,其車輛在一次充電後能行駛 408 英里,這遠遠超過了 Model 3 Long Range RWD 的 EPA 預估範圍 363 英里。
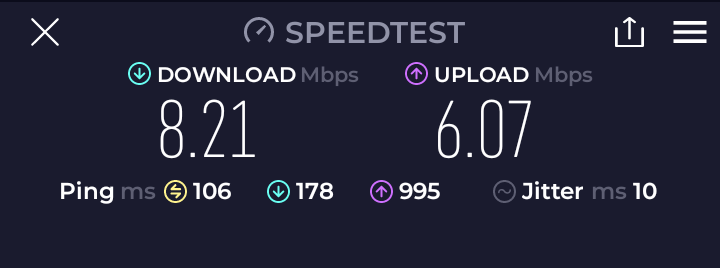
這位 Tesla 車主 @dkrasniy 在網上分享了一張車輛行程後的數據圖像。從 Model 3 車主的照片中可以看出,該車型在行駛過程中的平均能耗為 184 Wh/mi。雖然這顯示出該駕駛者在行駛過程中對油門的控制相當保守,但這一成就仍然相當值得注意。
在這輛新 Model 3 LR RWD 上,單次充電行駛 408 英里的範圍實在令人難以置信。— David (@dkrasniy) 2024 年 11 月 30 日
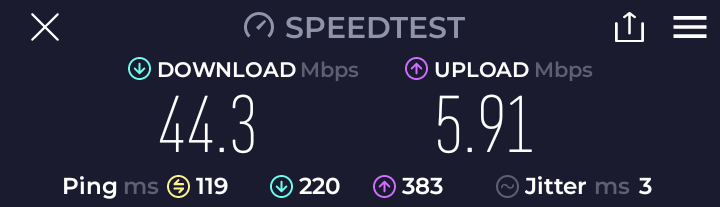
這並不是重新設計的 Model 3 轎車首次超過其額定範圍。在 YouTube 電動車頻道 Out of Spec Studios 於 9 月進行的一次測試中,Model 3 Long Range 全輪驅動版 (AWD) 雖然效率不如 Long Range RWD,但在以 70 英里每小時的速度行駛時,卻超過了其額定 EPA 範圍 341 英里,實際行駛了整整 370 英里。
Out of Spec 的 Kyle Conner 在測試中指出:「即使考慮到退化,新車在一次完美的並排比較中行駛的距離比舊車多了 60 英里。」
目前,Model 3 Long Range RWD 被列為 Tesla 最具價格競爭力的車型,這一點相當驚人,因為它也是該公司最具效率的車輛之一。在許多方面,這是一個希望體驗高端全電動車輛所能提供的客戶的良好入門選擇。其在續航方面似乎表現優異,更是為這款車增添了不少亮點。
深偽檢測工具作為 Google Chrome 瀏覽器擴展可用,提供一個“深偽分數”,用來判斷媒體是否真實。Hiya 聲稱其服務能在僅一秒的音頻中檢測出問題。人工智能技術中最令人擔憂的發展之一是深偽的興起,這些高度真實的音頻和視頻偽造品能夠誤導觀眾並擾亂商業活動。
隨著深偽工具變得越來越可獲得,對於可靠檢測方法的需求也在增長,特別是對於依賴準確信息做出關鍵決策的專業人士。Hiya 推出了其深偽聲音檢測器,這是一個免費的 Google Chrome 擴展,能快速識別被操控的音頻和視頻內容,並在幾秒鐘內提供結果,使得用戶能輕鬆識別可疑媒體。
對抗深偽的斗爭加劇。Hiya 聲稱其工具通過將 AI 驅動的檢測能力直接整合到瀏覽器中,為商業、記者和個人在日益複雜的信息環境中提供了一個實用的解決方案。深偽聲音檢測器利用 AI 的力量,以高達 99% 的準確率識別被操控的音頻和視頻。該工具分析在線內容中的聲音模式,並在幾秒鐘內提供結果,為用戶提供一種快速評估可疑材料的方法,無論音頻通道或語言如何。
幾個媒體和事實檢查機構,如 AFP Fact Check、RTVE.es、深偽分析單位和 TrueMedia.org,已經依賴 Hiya 的解決方案,微軟副主席兼總裁布拉德·史密斯最近也讚揚了這個工具,稱其為“利用良好的 AI 對抗壞的 AI 的優秀範例”。Hiya 的總裁庫什·帕里克表示:“深偽詐騙可能導致員工分享機密公司信息或暴露關鍵 IT 系統密碼。這些詐騙的後果是巨大的,特別是隨著深偽被越來越多地用於詐騙或勒索個人。”
大容量儲存解決方案的領導者Seagate Technology與領先業界的雲端儲存供應商 Dropbox 今 (6) 日舉辦一場座談會,探討資料儲存因應 AI 創新時代的需求,如何在現代資料中心發揮關鍵作用。Seagate 亞太及日本區業務副總裁 Futoshi Niizuma 與 Dropbox 基礎架構副總裁 Ali Zafar 兩人連袂出席,分享如何運用資料推動 AI 進步。
這場對談深入探討主要由 AI 等先進技術帶動的資料爆炸性成長,以及資料儲存在 AI 時代的關鍵作用。AI 應用範圍日益廣泛、效能持續提升且漸受信賴,如今的角色不再只是資料消耗者,而是成為強大的資料創造者,迎來富媒體 (rich media) 的復興年代。未來四年內,AI 生成的圖像和影像創作量預計增加 167 倍 1,產生數百 ZB 的新資料。為了讓 AI 模型持續演進,AI 將仰賴更豐富的資料、進行更多複製,也需要更長久的保留期,以提升訓練流程、減少偏差,同時提高整體的準確性和可靠度。
Ali Zafar 特別指出各產業創建資料的數量呈指數級成長。Dropbox 客戶所產生和儲存的資料皆多於以往,包括圖像、影像和多模態資料等豐富多樣的內容。組織若能取得更多資料,將有助於做出更有利的決策並減少偏差,進而得到更公正且準確的結果,對於醫療保健和財務等敏感領域尤其關鍵。
Futoshi Niizuma 則藉由檢視 AI如何在資料生成和消耗的無限循環中運作,分析資料儲存在應對資料增長態勢中的角色。輸入高品質的資料有助於 AI 進行學習和持續改善,建立更具智慧的模型,產出更出色的結果,輸出資料日益豐富多元,同時不斷強化 AI 的可信度。隨著資料循環持續增加,為了因應 AI 規模成長需求,儲存容量也同樣必須隨之擴充。
有效規劃容量和資源對於處理飛速成長的資料至關重要,而瞭解正確的儲存架構,更是管理大型語言模型訓練和資料密集型工作負載的必要條件。資料中心目前 90% 2 的 EB 資料量和企業工作負載儲存在硬碟上,此趨勢將得以憑藉 AI 最佳化架構而延續。AI 運算叢集仰賴記憶體和 SSD 來滿足即時需求,而網路 AI 儲存叢集則依靠更具成本效益的硬碟來儲存長期且龐大的資料量,而多數資料跨越不同儲存層後,最終將常駐於硬碟中。